硕士论文网第2020-10-26期,本期硕士论文写作指导老师为大家分享一篇
软件工程文章《基于软件工程中主流静态分析工具的分类模型》,供大家在写论文时进行参考。
本篇论文是一篇软件工程硕士论文范文,首先,我们对源代码分析报告中的各特征进行了简单的介绍。接着,在数据预处理部分,.对于:特征summary我们采用/NLP(Natural Language Processing)的相关方法进行处理,然后,针对数据量大且需要打标签的现实困难,我们提出了采用半监督学习算法来利用机器打标签的思路。最后,采用LightGBM进行分类模型的训练。
第一章 引言
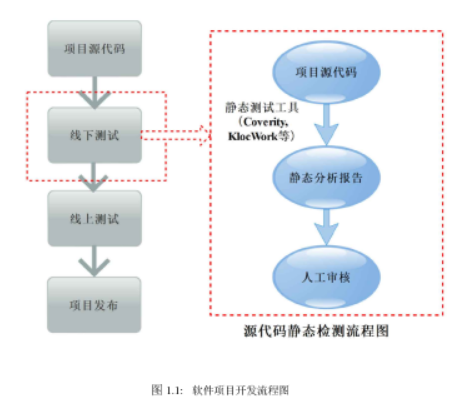
随着互联网的快速发展和软件项目复杂性的增大,软件安全问题越来越突出。一般来说,一个软件项g从开发到成功上线都会经历代码编写、线下测试和线上测试等几个环节,具体如图1.1。而项目的安全问题主要是由代码漏洞引起的。提高软件项目安全性的方法有很多,比如培养开发人员良好的编程素养,采用完善的开发模式等。而近年来,静态检测作为线下测试中一种高效的程序分析技术受到人们的麗视。静态检测是指不需要运行程序,接通过对代码的分析,发现其的漏洞。静态检测可以在代码编写完成后查找代码中的漏洞,因此非常方便和高效。源代码静态测试根据检测手段分为人工审查和专M具检测。审查代码的测试方式,因测试人员的评判标准不同,测试效果差异很大。专业的工具检测是基于规则的检查,这些规则是从事嵌入式系统开发的专家们积累的典型错误的集合。充分利用这些规则和静态测试工具,及时开展静态测试,可大大提高软件产品的正确性、安全性和可靠性。本文选取的分析工具主要采取市场上普遍认可的数据流分析技术,比如Coverity和KlocWork。这些工具也是目前商业领域最主流的静态分析工具。在实际项目中,如图1.1所示,获取到诊断报告后,需要由审核员评估代码缺陷的有效性。手动审计所有警报和修复己确认的代码漏洞所需的工作通常超出了项目的预估。审核员需要能够对警报进行分类的工具,这样可以有效的提高审核效率。本文描述了我们进行的研究,即采用分类模型来预测静态分析警报是否是真的代码错误。我们首先采用多个静态分析工具对同一项目代码进行扫描,得到诊断报告。然后,使用这些诊断报告分别创建警报分类模型,并测试这些模型。实验证明,我们提出的分类模型取得了很好的分类效果。由于不同工具生成的诊断报告中都含有对警报的一些描述,即自然语言描述。我们在数据预处理部分采用了当前比较主流的自然语言处理方式(分词、去除停用词、将文本转为TF-IDF向量和用LSI来保证向量的维度一致等技术)将文本数据转化为机器熟悉的数字向量,为模型训练做好数据准备。由于机器学习需要大量标记好的训练数据来训练模型,而数据标记又是一项庞大繁复的工作,因此我们尝试用半监督学习算法,使用少量己标记好的数据通过机器学习算法来标记剩余的大量数据,从而进一步提高项目效率。我们比较的是机器学习中经典的四种分类算法,即RF (Random Forest,随机森林)、CART(Classification And Regression Tree,分类与回归树)、XGBoost(extreme Gradient Boosting,极端梯度增强)和LightGBM。这些算法根据概率将警报分配到各个类,在模型复杂性、针对数据集大小等方面各有优劣。我们希望使用这些分类算法来创建模型,以便将诊断报告中的警报自动分类为预测正确或者预测错误,从而大幅度降低警报审核员的工作强度,提高实际工作中的项目效率。
第二章 研究现状
随着互联网技术的快速发展,静态分析技术也从最初简单的特定词分析发展到现在利用成熟的工具全面检测分析,保证了软件项目的高效率、高质量上线。在静态分析的相关研究中,由于不同项目对效率、安全等方面的需求有所差异,导致警报的分类和命名一直不曾统一。Delaitre的评级系统在分析静态工具有效性的研究中经历了多次演变,最终将用于描述警报的词汇确定为“securityrelated(与安全相关的)”,“quality-related(质量相关)”、“insignificant(无关紧要)”和“false(错误)”。Ciriell〇的分析只是使用了“C++测试问题”和“False Positive(假阳性)”两个词汇决定。Baca使用静态分析来改进软件安全性的工作中使用了三个词汇:“FalsePositive(假阳性)”表示未正确识别的错误不影响与安全性相关的指定参数、“Truepositive(真阳性)”表示正确识别的错误不影响与安全性相关的指定参数、“Security(安全性)”表示正确的警告可能传播导致用户的系统产生故障。Carlsson使用静态分析工具进行的研究中使用了四个词汇:“false Positive (假阳性)”、“possible securityimprovement(可能的安全改进)”、“security risk with consequences(带有后果的安全风险)”和“false negative(假阴性)”。Cifuentes描述了Oracle 内部对Parfait 静态分析工具的部署,他们的服务器使用“true”、“falsepositive”和“won’t fix”等词汇来描述每个代码库的历史扫描情况,包括夜间运行结果、总体报告状态和扫描结果。由于本文只针对分析报告产生后造成的人工审核量过大的问题进行研究,因此我们采用所有研究都认可的真假限定词:“False Positive”和“True positive”来对分析报告中的警报进行描述。Bessey等人在实践中发现了使用静态分析的许多问题。比如,一些忽略结构的工具,导致产生许多假阳性警报(程序中并不存在的bug),使用户错误的将这些假阳性警告标记为真正的bug,加重了程序员修改bug的工作量。Delaitre等人发现,在不复杂的基本测试用例中,静态分析工具平均能发现约20%的错误。他们使用了一组匿名静态分析工具进行扫描,发现复杂的控制流和数据流结构会显著降低这些工具的扫描准确率。由于单个静态分析工具对问题代码的覆盖范围有限(对某些错误发出警告,但对其他错误不发出警告),所以可以使用多个静态分析工具来查找更多的代码错误。这种方法会使警报数量剧增,并且其中包含了大量的误报。Beller等人发现大部分开源项目都没有与其工作流程紧密集成的静态分析工具,而且很多项目并不要求代码库是完全无警报的。Kong等人使用警报风险评级和置信度对警报进行优先级排序。他们认为如果一个警报是由多个工具报告的,则其优先级较之其它警报会更高,并且提供了3个代码库的实验分析结果。但是他们没有使用代码库的特征来对警报进行分类,他们的方法也不能分析比较复杂的置信度因子。例如,工具A、工具B和工具C有不同的置信度因子,若A为0.4,B为0.8,C为0.3,当工具A和工具C发出警报而工具B不发出警报时,我们更相信工具B的判断,认为此程序不含有错误。Meng等人[17]提出了一种合并多个工具扫描结果的方法,并给出了两个策略对结果进行优先级排序。他们先是根据警报的严重程度对警报进行排序,然后根据生成该类型警报的工具数量对代码中该位置的警报进行排序。这种方法并没有对警报的正确性进行分析。Kremenek利用工具和代码库的特性,根据每个静态分析工具的相关数据对警报进行排序?。但是,该方法对来自不同工具的警报集进行排序时,不做警报融合,只是单纯的使来自一个工具的所有警报的优先级低于来自另一个工具的所有警报的优先级。Heckman和Williams对警报的分类和优先级进行了广泛的调查,详细介绍了21项同行评审的研究。HeckmaiTMi用开发人员反馈的误报和修复真报,以及警报等级、特有数据等自适应地对警报进行分级。她的模型在只调查了20%的警报后,发现了81%的真正警报。Kremenek等人使用的公式适用于人工对静态分析工具输出的检测。由于人工审核人员都是从(当前)己排序警报集的顶部对每个警报进行审核,因此可以采用公式动态地利用相关信息对警报重新排序。Ruthruff等人构建了模型来预测警告是否为假阳性。如果为真,则预测开发人员是否会对缺陷采取行动(如果为真,则对项目本身无实质影响,但不太规则的代码格式及潜在影响是否需要修改则需要项目经理来决定)。他们采用了逻辑回归来预测,用到的特征包括程序大小、文件最近的更改历史、文件发布以来的文件年龄和最近的故障历史。在谷歌进行的案例研究中,生成的模型在预测假阳性方面的准确率超过85%,在识别真实警报方面的准确率超过70%。我们的工作就是继续采用谷歌的预测思想,但不是直接对代码文件的相关特征建模,而是对当前主流的静态分析工具结果建立一个针对其规则、警报严重性等该工具特有的规则属性的分类模型,使其在生成其它项目警报时能直接预测其假阳性的概率。同时,我们针对数据集需大量标注的情况,采用了半监督学习算法来进行数据标记。实验证明,我们提出的基于半监督数据标记的分类模型取得了很好的效果。
第三章 相关理论与技术介绍
1 自然语言处理
2 半监督学习
3 LightGBM
第四章 数据集介绍和实验设置
1 数据集介绍
2 评价指标
3实验设置
第五章 实验结果及分析
1 实验I
2 实验II
第六章 总结与展望
人们迈入信息时代的步伐日益稳健,互联网应用迎来了高速的创新与发展,随之而来的信息与网络安全问题也前所未有的严峻。通常意义下,网络安全的最大威胁是程序上的漏洞,程序漏洞检测主要分为线上测试和线下测试,其中线上测试也就是运行时检测,线下测试就是本论文研究的静态代码扫描分析。本文主要研究了在静态代码扫描分析中,由扫描工具得到的扫描报告中大量的False Positive造成报告审核的难度增大问题,提出解决方案。针对扫描工具生成的扫描报告中最多仅有30%是真正的程序bug,本论文提出利用人工智能的方式来解决。本文采用机器学习领域的主流模型LightGBM对扫描得到的警报进行类别预测,使机器能够自动判断扫描报告中每一个警报的可信度,从而大大提高扫描报告的审核效率。在数据预处理部分,由于扫描工具得到的扫描报告中含有Category(警报类型)、Summary(警报基本描述)等特征都是自然语言,本文采用了分词、转化为TF-IDF向量和LSI等自然语言的基本处理方法将机器无法识别的语言符号转变为可以识别的数字向量,为后期的模型训练做好数据准备。在模型训练阶段,考虑到单一模型的局限性,我们采用了其它三个比较主流的机器学习模型作为基准模型与我们提出的模型进行实验对比分析,来进一步论证本论文提出的模型LightGBM有着更好的分类效果。另外,由于人工智能模型算法对数据极为敏感,考虑到模型的稳定性和泛化性能,本论文用了四个主流静态工具进行实验。由四个数据报告上的实验结果可以得出,本论文提出的模型对于不同的数据报告都有很好的表现。最后,观察实验结果发现,其它三个基准模型也有相对很好的分类效果,这也说明了人工智能领域的算法模型在静态分析领域有着很好的应用前景。随着软件复杂性的增大,静态扫描工具经常要面临数量过万的代码文件,从而工具检测出的警报也日益增多。然而,分类模型的训练需要大量打好标签的数据,这就使得我们必须面临数据标记的困难。针对这一问题,本论文提出了利用半监督学习算法通过机器自动为数据集打标签,这样可以节约很大的人力标记成本。首先,人工标记一小部分的数据。然后采用这一小部分的人工标记数据通过S3VM训练模型,经过一定的迭代,不断训练调节惩罚系数,预测未打标签的数据,直到满足相应条件。这时所有的数据都被打上了合适的标签。最后用己经打好标签的数据进行模型训练即可。从实验II结果可以看出,同样的数据集,与人工标记相比,机器标记只损失了不到3%的分类效果。所以,我们可以给出结论,在面临比较庞大的软件项目的静态扫描问题时,可以采用半监督学习算法为数据打标签之后直接进行模型训练,这样可以大幅度提高项目扫描报告的审核效率。从本论文的研究成果可以看出,人工智能算法在软件工程领域有很好的使用前景。虽然本论文只涉及了软件工程中静态分析这一子领域,但模型的分类效果却相当好。这为人工智能在软件工程中的使用奠定了很好的基础,可以视为一个良好的开端。本论文的研究也有很多局限性。针对不同的局限性,未来所做的工作主要集中在以下几个方面:(1)我们的数据集只使用了公共领域比较认可的CWE(Common Weakness Enumera-tion)标准[29]来进行数据标记,同时扫描工具也采用了与之相符的主流商业静态扫描工具。在软件工程领域,不同的项目背景与项目所需解决的问题千差万别,一般的社交软件用公共的CWE标准即可。但其它行业的软件项目所用的标准也都有所不同,比如汽车领域就更常用MISRA(The MotorIndustry Software Reliability Association)C标准。本论文由于篇幅所限,没有对其它标准下的模型分类效果进行进一步的实验分析,下一步我们就针对不同的标准,继续实验分析,完善我们的分类模型。(2)在数据预处理模块,我们对含有自然语言的特征只是做了简单的向量化处理,这样提取的信息很有限。自然语言处理是人工智能主要的研究分支之一。如今,很多公司面对大量的自然语言数据纷纷成立了NLP实验室用于研究自然语言数据中的信息提取。本论文致力于人工智能模型在软件工程领域的尝试,并未着重研究自然语言数据的信息提取。下一步我们将考虑,采用更专业的自然语言处理方式,比如知识图谱?等,从扫描报告中的自然语言部分提取更多的信息,进而进一步提高模型的分类效果。(3)本论文只着眼于人工智能在软件工程中静态代码扫描部分的运用,在其它各部分的使用目前还是处于零尝试状态。人工智能在广告、电商等行业都取得了很好的成果,这让人们充分感受到了人工智能所带来的高效率、高性能。然而,在软件工程领域,人工智能的尝试几乎没有。接下来我们将进一步考虑人工智能在安全、测试、基本代码编写等软件工程各子领域的尝试,让人工智能的高效率惠及软件工程的各个领域。
该论文为收费论文,请扫描二维码添加客服人员购买全文。

以上论文内容是由
硕士论文网为您提供的关于《基于软件工程中主流静态分析工具的分类模型》的内容,如需查看更多硕士毕业论文范文,查找硕士论文、博士论文、研究生论文参考资料,欢迎访问硕士论文网软件工程栏目。
 首页
首页 毕业论文
毕业论文 硕士论文
硕士论文 博士论文
博士论文 学位论文
学位论文 在职硕士
在职硕士 职称论文
职称论文 研究生论文
研究生论文 留学生论文
留学生论文