硕士论文网第2021-07-13期,本期硕士论文写作指导老师为大家分享一篇
软件工程测试论文文章《优秀工程硕士毕业论文三篇赏析(三)》,供大家在写论文时进行参考。
摘要阐述了围绕软件工程大数据的汇聚组织、知识表示提炼、软件工具智能化和智能开发服务环境等关键技术开展的一系列研究工作,建立了基于大数据的软件智能化开发技术体系,研发关键性的软件智能化开发工具,形成了“人-工具-数据”融合的新一代软件智能化开发环境,并构建了软件智能化开发云平台。面向万众创新的社会需求,构建了服务大众的公共服务平台;针对企业创新能力的提升,提供了智能化的企业软件开发环境。
关键词软件复用;大数据;智能化软件开发;知识图谱;推荐
1引言
以开源软件为代表的互联网软件开发具有边界开放、群体分散、交付频繁、知识复杂等特征。与此同时,企业软件开发也逐渐转向以开发运维一体化(DevOps)为特征的云化开发平台。这些网络化开发方式产生了包含源代码、缺陷报告、版本历史、测试用例等在内的全生命周期数据[1]。例如,开源软件社区GitHub已经集聚了超过2.7亿个软件项目,软件开发问答网站StackOverflow已经积累了超过1700万个与软件开发相关的问题。这些数据中蕴含的规律可以通过统计和机器学习等技术进行吸收和泛化,用于构造各种智能化的软件工程工具[2]。智能化软件开发一直是软件工程追求的核心目标之一。学术界著名的以软件开发智能化为核心主题的自动化软件工程(ASE)会议始于20世纪80年代。近年来,在软件工程领域顶级会议ICSE、FSE等中出现了越来越多基于数据、知识驱动的开发智能化技术研究。例如,于2001年发起的软件仓库挖掘会议(MSR)已经得到了广泛关注,并开启了一个重要的软件工程研究子领域。2010年,RobillardMP等人[3]综述了软件工程中的智能推荐系统,指出这些系统在大范围的软件开发活动(如代码复用、软件维护等)中显著地提升了软件开发者的工作效率与质量。软件开发中的知识获取与应用一直是产业界关注的焦点之一。软件开发问答网站StackOverflow利用专家回答的群智机制,提供了大量软件开发问题的答案。Eclipse和VisualStudio等集成开发环境(integrateddevelopmentenvironment,IDE)都提供了代码自动补全功能。此后流行的IntelliJIDEA则将智能编码支持作为特色,提供了智能化代码规范检查、自动生成Java规范的基础方法框架、自动补充
方法或类代码框架等智能推荐支持。近年来,Eclipse和VisualStudio都在云开发平台方面取得了突破,在云端可以汇集大量开发数据,为更高层次的基于大数据的开发智能化提供了基础平台。国内主要软件工程研究团队在此方面也开展了大量的研究工作。北京大学2012年提出了知识驱动的软件复用方法;南京大学在基于数据的软件分析、测试方面进行了算法、工具和实践研究;中国科学院软件研究所基于云平台和数据分析技术,在软件运行时测试和演化方面开展研究;北京航空航天大学在开源软件数据的基础上研究了开发人员推荐问题;国防科技大学在开源数据收集和知识获取方面进行了大量的工作,维护并运行了Trustie社区和网络群体化软件开发环境。国内的浪潮通用软件有限公司、金蝶软件(中国)有限公司等也在获取开发人员操作、数据等方面研发了相应的工具环境;CSDN和OSCHINA等在软件开发技术论坛、代码托管和软件资源汇聚方面建立了大规模的社区。当前,软件智能化开发成为热点的关键原因在于新时代带来的技术发展的新环境:开源及企业软件开发产生了大数据源,机器学习和信息检索技术的发展提供了知识获取的核心支撑,企业领域工程的广泛实践积累了大量的领域资源。然而,作为智能化软件开发基础的软件开发数据具有规模巨大、碎片分散、快速膨胀的特点。在此基础上实现智能化软件开发支持仍然需要解决一系列基础性的数据采集分析以及知识抽取利用等方面的问题,并以智能推荐、问答等方式提升软件开发工具的智能程度,提高软件开发的质量和效率。在此基础上,智能化的软件工具可以基于数据和知识向开发人员提供推荐、检索和问答等方面的智能化支持。围绕相关方面,学术界和工业界已经开展了大量的技术研究和实践探索。然而,从总体方法论和技术体系来看,目前的研究和实践探索仍然局限于特定的技术关注点,使用的数据都是针对特定问题本身进行采集的,缺少大数据环境支撑的跨领域智能化技术研究,也没有形成完善的技术体系和环境。为此,笔者团队在国家重点研发计划项目“基于大数据的软件智能开发方法和环境”的支持下,围绕软件工程大数据的汇聚组织、知识表示提炼、软件工具智能化和智能开发服务环境等关键技术开展研究工作,建立基于大数据的软件智能化开发技术体系,研发关键性的软件智能化开发工具,形成“人-工具-数据”融合的新一代软件智能化开发技体系和环境,并构建软件智能化开发云平台。本项目构建的基于大数据的软件智能化开发方法和环境面向万众创新的社会需求,运行服务大众的公共服务平台;针对企业创新能力提升,提供智能化的企业软件开发环境。本文将从系统架构、核心技术、应用效果3个方面介绍基于大数据的软件智能化开发方法与环境。
2系统架构
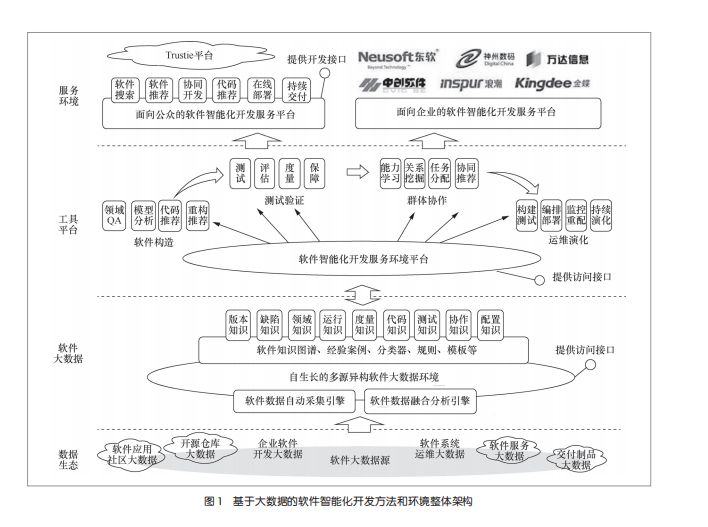
基于大数据的软件智能化开发方法与环境整体技术架构如图1所示。整个方法体系和环境以开源及企业软件项目代码仓库、交付制品、部署和运维监等多种类型的软件开发数据源为基础,包含软件大数据汇聚及知识提炼、软件智能化开发支持、软件智能化开发服务3个层次。其中,软件大数据汇聚及知识提炼通过自动化的方法采集和汇聚各种类型的软件开发数据,形成自生长的多源异构软件大数据环境,在此基础上,以知识图谱、经验案例、分类器、规则、模板等多种形式提炼和抽取各种软件开发知识。软件智能化开发支持从软件构造、测试验证、群体协作、运维演化4个重要的方面构建相应的工具平台和支撑环境,为相应的软件开发活动提供智能化支持。软件智能化开发服务基于以软件仓库为中心的分布式智能化开发环境集成技术,构建软件智能化开发云环境运行体系结构与集成框架,实现高可扩展的智能开发环境集成与部署,从而建立面向公众和企业的软件智能化开发
服务平台。
(1)软件大数据汇聚及知识提炼 基于主动感知、定向采集、多源关联、增量检测等技术,构建软件工程大数据处理体系结构与支撑系统,形成自生长的多源异构软件大数据环境。建立软件大数据的数据分类和数据汇聚、收集和整理技术体系,研发了相应的采集、存储和服务平台,原始数据、处理后数据以及元数据等不同类型的数据涵盖开发、交付、应用等不同阶段。在此基础上,利用自然语言处理、深度学习、数据挖掘、优化搜索等智能化技术,建立软件开发智能推荐技术研究体系,基于源数据提炼知识图谱、代码模式、主题模型等核心软件知识,形成一批智能推荐、问答技术与工具。
(2)软件智能化开发支持围绕软件开发中的软件构造、测试验证、群体协作、运维演化4个重要方面,分别形成相应的智能化工具体系,提供数据驱动的智能化推荐和优化技术。
●在软件构造方面,构建以代码库为核心的软件构造大数据环境以及相应的软件构造知识分析和提炼方法,提供软件构造智能问答、软件开发知识图谱可视化、代码生成与补全、自动化重构推荐等智能化软件构造支持。
●在测试验证方面,采用机器学习、启发式搜索、自然语言理解等智能化途径,面向测试用例生成、代码模型检验、静态分析缺陷警报确认、程序缺陷定位和修复等软件质量保障的多个方面提供复杂软件测试与验证智能化支持。
●在群体协作方面,基于软件大数据的收集与分析构建了软件开发者知识库,形成基于多源软件大数据的开发者知识库体系结构,提供基于学习曲线的开发者能力动态刻画方法和跨社区的开发者画像等智能化支持,同时构建了大规模开发者智能协作支撑环境。
●在运维演化方面,汇聚了以Docker镜像为代表的大规模开发运维一体化数据,形成了自生长、可追溯的领域数据集合。通过智能化持续集成与持续部署流水线系统等一系列工具系统,形成了面向开发运维一体化的运行演化智能支撑环境,提升了开发运维一体化过程的动态调节能力。
(3)软件智能化开发服务在软件智能化开发技术与工具的基础上,通过以软件仓库为中心的分布式智能化开发环境集成技术,构建软件智能化开发云环境运行体系结构与集成框架,实现高可扩展的智能开发环境集成与部署,建立面向公众和企业的软件智能化开发服务平台。目前已经基于Trustie平台,通过
提升改进形成了软件智能化开发服务环境平台IntelligentDE,同时基于EclipseChe架构实现了智能化推荐工具的整体集成。最终建立的软件智能化开发服务平台面向公众提供网络化的智能化开发服务,同时面向企业提供私有化部署的智能化开发支持。
3核心技术
基于大数据的软件智能化开发方法与环境包括7个方面的核心技术:软件大数据汇聚、软件知识提炼、智能化软件构造、智能化测试验证、智能化协作、智能化运维演化、智能化开发服务环境。
3.1软件大数据汇聚
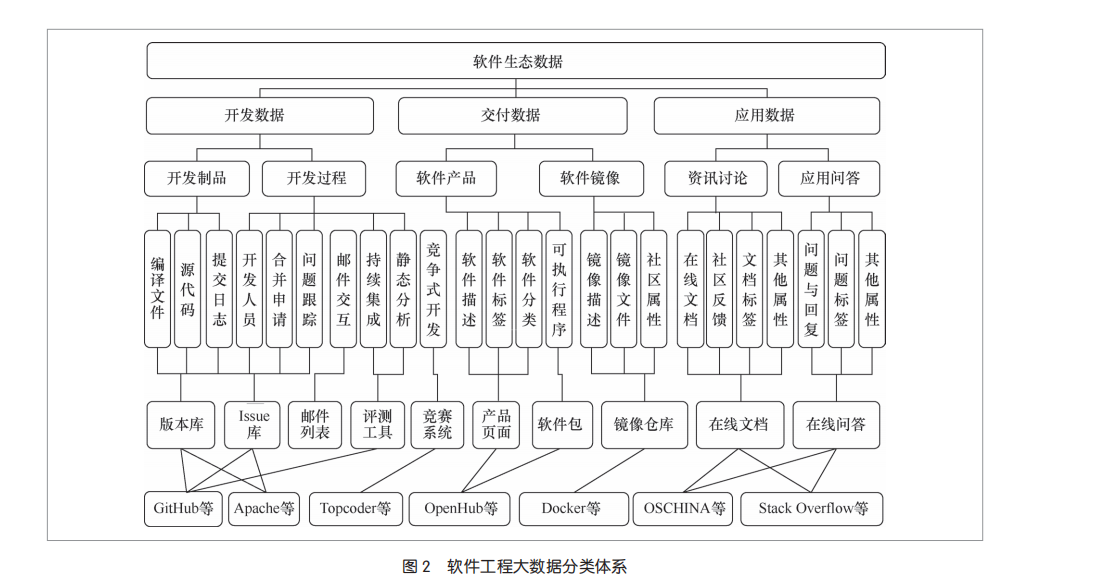
软件工程大数据以代码、文档、开发记录等文本为主体,语义丰富。通过对当前软件工程领域的数据进行分析,从数据类型、数据格式、数据用途和所属的软件生命周期阶段等多个方面进行归纳,建立了综合互联的软件工程大数据分类体系(如图2所示),以支持多维度、多谱系、贯通性的软件知识提炼和智能释放。该体系包括开发数据、交付数据和应用数据三大类,分别又细分为多个子类,并将该分类体系与当前的多种软件仓库、社区和论坛的具体数据格式建立了映射。围绕软件工程大数据分类体系,面向智能开发服务建立了贯穿数据源、数据存储、数据处理与数据服务的全链条软件大数据框架,实现对海量软件工程数据的采集、分析和应用等全链条管理。整个软件工程大数据管理框架与环境包括数据源、数据存储、数据处理与数据实例4个层次。
●数据源:软件工程大数据涵盖开发、发布、应用、运维等不同过程、不同类型和不同源的数据,包括版本库、代码仓库、配置制品、软件镜像等。通过相应的爬虫可以实现对这些多源异构数据的实时、增量抓取和汇聚。
●数据存储:主要实现对大规模异构软件工程大数据的高效存储和访问。
●数据处理:围绕特定的任务和目标,将存储的数据按需展开,并进行相应的处理,形成软件知识库,如软件知识图谱通过数据解析、融合等技术进行数据的二次加工和处理;通过分析不同数据类型之间的关联和依赖、基于图数据库等存储技术构建软件领域知识图谱,进一步通过数据按需展开机制有效降低存储资源的占用情况。
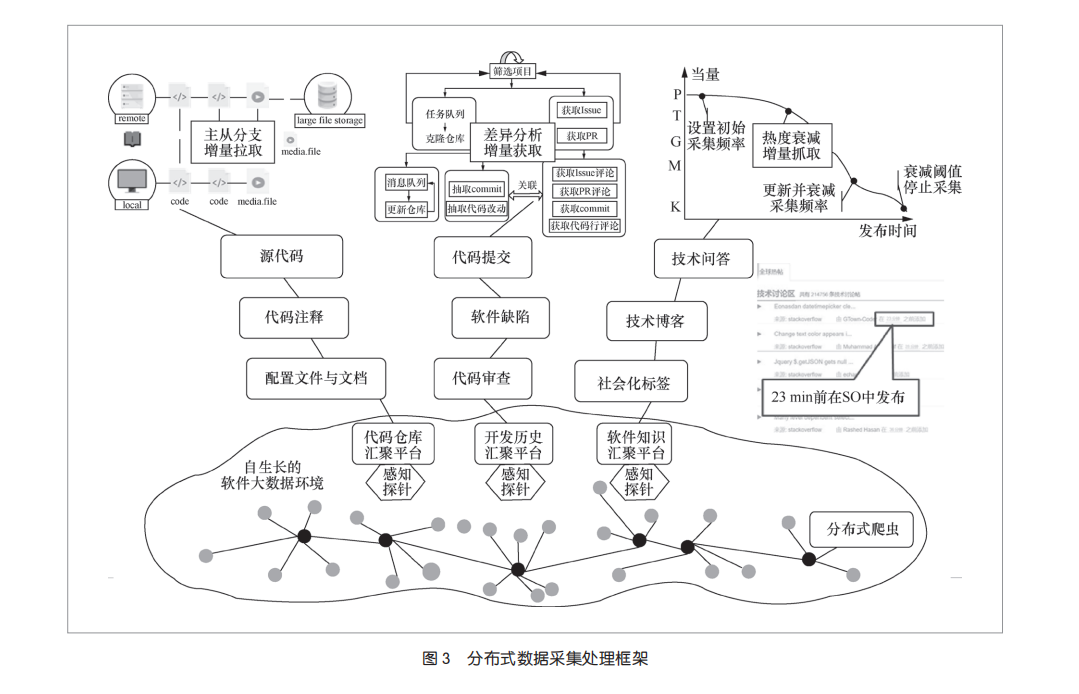
●数据实例:通过丰富的接口和服务,针对不同的需求与应用提供相应的数据服务,针对不同类型的数据,对外提供不同的数据服务,包括以项目为中心的数据服务、以测试为目标的数据服务、以人为中心的数据服务、以运维为目标的数据服务等。在此基础上,针对网页数据、版本库数据、缺陷库数据等,提出了主动感知、定向采集、多源关联和增量检测等一系列关键技术,设计构建如图3所示的分布式数据采集处理框架,部署了分布式爬虫,实现了基于网页爬虫和应用程序接口(applicationprogramminginterface,API)的数据获取、数据包下载等多种收集方式。其主要特点如下:
●构建了大规模多类型的分布式爬虫,实现对全球数十个开源社区的代码仓库、开发历史及软件知识等类型数据的主动感知、定向采集和增量更新;
●对于异构的代码数据和代码历史提交等数据,基于Git版本管理工具实现了差异分析和增量拉取;
●对于软件知识数据,通过对不同网站帖子的历史浏览等数据进行分析,形成帖子的关注度衰减模型,从而基于该模型确定对每个网站帖子的更新抓取频率。采用实时监测、元数据本地存储、按需获取与构建的模式,在兼顾可控性和效费比的情况下,针对不同类型数据的软件数据进行汇聚、收集和整理,实现对全球PB级开源数据(包括原始数据、处理后数据以及元数据)的自主掌控。采用分散存储、平台汇聚的模式提供共享管理和在线访问统一入口,部署于UCloud和阿里云等公有云,并提供统一的汇聚数据说明和访问入口。在此基础上,建立了如下3个软件工程大数据获取与服务平台。
(1)全球开源软件检索与分析平台OSSEAN针对软件问答社区、开源软件项目、软
件开发工具、开发者等类型的数据进行了汇聚和收集整理,构建了面向全球开源软件的检索与分析平台OSSEAN。其包括3层:数据获取层、数据分析层、数据展示层。其中,数据获取层完成数据的采集工作,为平台提供高效、稳定、持续、准确的数据服务;数据分析层对数据获取层获取的页面信息进行抽取,提取出每个页面中的关键信息,并对抽取结果进行验证,同时通过数据挖掘对抽取的数据进行分析(例如社区关联、软件评估等);数据展示层对得到的数据处理结果按照平台展示的数据格式进行处理,并将处理结果存放于数据缓冲池中,为平台的展示提供数据支持。目前,OSSEAN的数据获取模块已覆盖全球20多个主要开源社区,通过持续监控,实时抓取了超过1400万个开源项目/仓库元数据以及超过2000万条在线讨论数据,同时提供了开源软件分析、检索、排序以及热点话题分析等服务。
(2)软件工程大数据共享平台SBD依托Trustie平台,采用开放共享、分散存储、平台汇聚、按需获取的方式,设计和制定了多源异构的统一的大数据门户,形成大规模软件工程大数据共享平台SBD。共享平台采用分散存储、平台汇聚的模式提供共享管理和在线访问统一入口,平台部署于UCloud和阿里云,提供汇聚数据说明及访问入口。目前,平台通过原始数据、处理后数据以及元数据等形式实现了对涵盖开发、交付、应用等不同阶段的软件工程数据的跟踪、获取,为软件工程研究、智能化开发工具等提供不同类型的数据和服务。
(3)软件交付制品获取与管理平台RAISE针对Docker镜像设计了一种海量数据汇聚、管理、知识抽取[4]和质量评价的系统化方案和服务,实现了增量式、高并发的Docker数据汇聚和管理方法,支持对DockerHub上百万级Docker数据的自动获取与增量更新,实现了数据的可发现和可追踪。研发了面向软件交付制品(Docker镜像)的数据获取与在线管理服务平台RAISE,以提高制品质量、制品统一管理和实现高效复用为目标,提供多维度的Docker制品信息统计与可视化展示,支持Docker镜像的分析、检索、排行、评价和修复推荐等。
3.2软件知识提炼
为了实现智能化软件开发目标,需要通过多种手段从这些数据中提炼软件知识,形成智能化软件开发支撑能力。针对这一目标,以机器学习、知识图谱、数据挖掘、信息可视化等智能化技术为基础,以检索、推荐、问答、查错等服务形式为呈现方式,形成了一系列软件知识提炼与应用方法体系。其中,基于机器学习和知识图谱这两种主要的智能化分析技术形成的软件开发知识提炼方法与技术体系分别如图4和图5所示。基于机器学习(含深度学习)的智能化分析以源代码、软件开发库、项目开发文档、众包开发网站、众包问答、API文档等软件开发数据为基础,通过训练数据准备和模型训练形成具备智能化推荐能力的服务形态。其中训练数据准备和模型选择是关键。训练数据准备阶段的目的是从原始的软件开发数据中抽取符合智能化推荐能力需要的训练样本,例如针对API使用代码推荐的API/控制单元与代码上下文的对照关系、针对缺陷修复分派推荐的缺陷报告与修复者及所模块的对照关系等。为此,本项目通过程序分析、信息抽取和过滤等多种分析方法,从原始软件开发数据中抽取相关信息,并形成包含所需对照关系的训练样本。在模型选择上,本项目广泛使用了先进的深度学习技术,包括面向API使用代码推荐的Tree-LSTM模型、面向缺陷4应用效果面向公众的软件智能开发服务平台通过衔接高校、科研机构、软件园区、软件企业等利益相关方,降低软件开发门槛、释放软件开发潜力,推动软件驱动的“产学研用”创新创业生态的构建。在多源异构软件工程大数据的汇聚与管理方面,研究并建立了覆盖“开发-交付-应用”的软件生命全周期的数据分类体系,突破主动感知、定向采集、多源关联、增量检测等关键技术,构建了自生长的软件工程大数据共享平台SBD。SBD以原始数据、处理后数据以及元数据等形式汇聚了全球主流开源社区的开源软件项目、软件问答讨论、软件开发工具、Docker镜像、开发者等不同类型的数据;通过对数据源进行感知与监测,利用元数据分析比对等技术实现对数据变化的感知和追踪,实现持续演化的软件工程大数据的增量式获取,提升对开源软件大数据的掌控能力。目前,平台上可跟踪和获得的数据总量超过1.5PB,其中集中存储约25TB,分散存储约217TB,实时监控数据约1278TB。在数据与工具开源方面,针对Apache开源软件基金会中的192个开源软件项目(共计482.48GB软件项目数据),分别构建了相应的软件项目知识图谱。以ApacheLucene项目的知识图谱为例,共抽取出了378897个实体,以及这些实体之间的1902683条关联关系;在此基础上,对外提供了软件项目智能问答服务。开发者可以提出自然语言问题,系统基于知识推理在知识图谱以及项目文档中进行搜索,并给出答案。同时,项目将项目团队自主研发的、自主可控的35项智能开发工具与相关软件数据进行了汇聚整理,开源到木兰开源社区。在国内开源生态建设方面,项目支持GCC建成了面向“开放计算架构+开源软件技术”的中国绿色计算开源技术和产品开发社区,汇聚了国内的企业团队和大众贡献者;基于Trustie构建的中国绿色计算开源技术已经发展成我国最大的ARM开源开发和创新社区,有效支持了产、学、研、用各界的开源开发和评测活动;支持新一代人工智能产业技术创新联盟OpenI启智开源社区的建设,推动人工智能领域开源开放协同创新生态的构建;支持的可控开源创造行动是我国2020年启动的重大创新体系建设计划,核心是激活和汇聚开放群体智慧和贡献,构建一种可持续发展的生态。在科学研究创新方面,项目有效地帮助了micROS机器人操作系统团队、NuBot国际顶尖机器人竞技团队、Trustie群体化软件开发研究团队等解决了智能化软件开发和持续性质量改进等难题。在高校实践教学方面,智能化实践学习平台头歌(EduCoder)支撑产教各界开发了超过6.9万个在线计算机训练项目、391万个开源代码仓库,各类师生和开发者超过80万人,提供实践课程3900余门。此外,项目还参与支撑了3届“全国高校绿色计算创新大赛”,参赛人数总量超过2万人次。
...........................
5结束语
围绕基于大数据的软件智能开发方法和环境,项目团队提出了一套大数据驱动的软件智能化开发方法,涉及软件开发多个主要过程中的智能化支撑技术。项目团队研发了一批软件智能化开发工具原型系统,在基于知识图谱的软件开发问题复杂查询、数据驱动的测试、智能化群体协作、智能化开发运行一体化决策等方面均提供了基于软件大数据的智能推荐和开发支持。基于对国际开源软件社区级技术的整体分析和研究,项目团队建立了一套互联网及开源软件数据资源的获取汇聚技术和方法,以及融合利用技术方案,目前可以跟踪和获取超过1.5PB的软件工程数据,分析监测了392万个开源软件,为全球开源领域的4397万名开发人员建立了画像,提升了我国对此类数据的掌控能力。在前期国家计划形成的软件资源共享与群智开发平台基础上,项目团队进一步发展了软件开发中的数据智能支撑功能,形成了较为完善的云化开发平台,并对外提供公共服务。目前,开源开发平台注册的各类用户约41.5万人,开源项目1.5万个;开源教育平台汇聚了5.4万个开源训练项目,293万个开源代码仓库,来自982所高校与企业的1.1万名注册教师、33.2万名注册学生和开发者,提供实践课程1600余门。在6家大型软件开发企业中取得了一批应用示范的成果,显著提高了软件企业的生产效率和质量;形成了一个自主可控的软件开发共享服务的技术框架,并基于此方案支持了一批国内开源社区的支撑环境建设,包括“云计算与大数据”重点专项的集成平台的环境建设。
参考文献:
[1]ZHANGDM,HANS,DANGYN,etal.Softwareanalyticsinpractice[J].IEEESoftware,2013,30(5):30-37.
[2]HINDLEA,BARRET,GABELM,etal.Onthenaturalnessofsoftware[J].CommunicationsoftheACM,2016,59(5):122-131.
[3]ROBILLARDMP,WALKERRJ,ZIMMERMANNT.Recommendationsystemsforsoftwareengineering[J].IEEESoftware,2010,27(4):80-86.
[4]CHENW,ZHOUJH,ZHUJX,etal.Semi-supervisdlearningbasedtagrecommenationforDockerrepositories[J].JournalofComputerScienceandTechnology,2019(5):957-971.
[5]LINZQ,ZOUYZ,ZHAOJF,etal.Improvingsoftwaretextretrievalusingconceptualknowledgeinsourcecode[C]//201732ndACM/IEEEInternationalConferenceonAutomatedSoftwareEngineering.Piscataway:IEEEPress,2017:123-134.
[6]CHENC,PENGX,SUNJ,etal.GenerativeAPIusagecoderecommendationwithparameterconcretization[J].ScienceChinaInformationSciences,2019,62(9):51-72.
该论文为收费论文,请扫描二维码添加客服人员购买全文。

以上论文内容是由
硕士论文网为您提供的关于《优秀工程硕士毕业论文三篇赏析(三)》的内容,如需查看更多硕士毕业论文范文,查找硕士论文、博士论文、研究生论文参考资料,欢迎访问硕士论文网软件工程测试论文栏目。
 首页
首页 毕业论文
毕业论文 硕士论文
硕士论文 博士论文
博士论文 学位论文
学位论文 在职硕士
在职硕士 职称论文
职称论文 研究生论文
研究生论文 留学生论文
留学生论文